Reinforcement Learning Tips and Tricks¶
The aim of this section is to help you doing reinforcement learning experiments. It covers general advice about RL (where to start, which algorithm to choose, how to evaluate an algorithm, …), as well as tips and tricks when using a custom environment or implementing an RL algorithm.
General advice when using Reinforcement Learning¶
TL;DR¶
- Read about RL and Stable Baselines
- Do quantitative experiments and hyperparameter tuning if needed
- Evaluate the performance using a separate test environment
- For better performance, increase the training budget
Like any other subject, if you want to work with RL, you should first read about it (we have a dedicated resource page to get you started) to understand what you are using. We also recommend you read Stable Baselines (SB) documentation and do the tutorial. It covers basic usage and guide you towards more advanced concepts of the library (e.g. callbacks and wrappers).
Reinforcement Learning differs from other machine learning methods in several ways. The data used to train the agent is collected through interactions with the environment by the agent itself (compared to supervised learning where you have a fixed dataset for instance). This dependence can lead to vicious circle: if the agent collects poor quality data (e.g., trajectories with no rewards), then it will not improve and continue to amass bad trajectories.
This factor, among others, explains that results in RL may vary from one run to another (i.e., when only the seed of the pseudo-random generator changes). For this reason, you should always do several runs to have quantitative results.
Good results in RL are generally dependent on finding appropriate hyperparameters. Recent algorithms (PPO, SAC, TD3) normally require little hyperparameter tuning, however, don’t expect the default ones to work on any environment.
Therefore, we highly recommend you to take a look at the RL zoo (or the original papers) for tuned hyperparameters. A best practice when you apply RL to a new problem is to do automatic hyperparameter optimization. Again, this is included in the RL zoo.
When applying RL to a custom problem, you should always normalize the input to the agent (e.g. using VecNormalize for PPO2/A2C) and look at common preprocessing done on other environments (e.g. for Atari, frame-stack, …). Please refer to Tips and Tricks when creating a custom environment paragraph below for more advice related to custom environments.
Current Limitations of RL¶
You have to be aware of the current limitations of reinforcement learning.
Model-free RL algorithms (i.e. all the algorithms implemented in SB) are usually sample inefficient. They require a lot of samples (sometimes millions of interactions) to learn something useful. That’s why most of the successes in RL were achieved on games or in simulation only. For instance, in this work by ETH Zurich, the ANYmal robot was trained in simulation only, and then tested in the real world.
As a general advice, to obtain better performances, you should augment the budget of the agent (number of training timesteps).
In order to achieve the desired behavior, expert knowledge is often required to design an adequate reward function. This reward engineering (or RewArt as coined by Freek Stulp), necessitates several iterations. As a good example of reward shaping, you can take a look at Deep Mimic paper which combines imitation learning and reinforcement learning to do acrobatic moves.
One last limitation of RL is the instability of training. That is to say, you can observe during training a huge drop in performance.
This behavior is particularly present in DDPG, that’s why its extension TD3 tries to tackle that issue.
Other method, like TRPO or PPO make use of a trust region to minimize that problem by avoiding too large update.
How to evaluate an RL algorithm?¶
Because most algorithms use exploration noise during training, you need a separate test environment to evaluate the performance
of your agent at a given time. It is recommended to periodically evaluate your agent for n test episodes (n is usually between 5 and 20)
and average the reward per episode to have a good estimate.
As some policy are stochastic by default (e.g. A2C or PPO), you should also try to set deterministic=True when calling the .predict() method, this frequently leads to better performance. Looking at the training curve (episode reward function of the timesteps) is a good proxy but underestimates the agent true performance.
Note
We provide an EvalCallback for doing such evaluation. You can read more about it in the Callbacks section.
We suggest you reading Deep Reinforcement Learning that Matters for a good discussion about RL evaluation.
You can also take a look at this blog post and this issue by Cédric Colas.
Which algorithm should I use?¶
There is no silver bullet in RL, depending on your needs and problem, you may choose one or the other. The first distinction comes from your action space, i.e., do you have discrete (e.g. LEFT, RIGHT, …) or continuous actions (ex: go to a certain speed)?
Some algorithms are only tailored for one or the other domain: DQN only supports discrete actions, where SAC is restricted to continuous actions.
The second difference that will help you choose is whether you can parallelize your training or not, and how you can do it (with or without MPI?).
If what matters is the wall clock training time, then you should lean towards A2C and its derivatives (PPO, ACER, ACKTR, …).
Take a look at the Vectorized Environments to learn more about training with multiple workers.
To sum it up:
Discrete Actions¶
Note
This covers Discrete, MultiDiscrete, Binary and MultiBinary spaces
Discrete Actions - Single Process¶
DQN with extensions (double DQN, prioritized replay, …) and ACER are the recommended algorithms. DQN is usually slower to train (regarding wall clock time) but is the most sample efficient (because of its replay buffer).
Discrete Actions - Multiprocessed¶
You should give a try to PPO2, A2C and its successors (ACKTR, ACER).
If you can multiprocess the training using MPI, then you should checkout PPO1 and TRPO.
Continuous Actions¶
Continuous Actions - Single Process¶
Current State Of The Art (SOTA) algorithms are SAC and TD3.
Please use the hyperparameters in the RL zoo for best results.
Continuous Actions - Multiprocessed¶
Take a look at PPO2, TRPO or A2C. Again, don’t forget to take the hyperparameters from the RL zoo for continuous actions problems (cf Bullet envs).
Note
Normalization is critical for those algorithms
If you can use MPI, then you can choose between PPO1, TRPO and DDPG.
Tips and Tricks when creating a custom environment¶
If you want to learn about how to create a custom environment, we recommend you read this page. We also provide a colab notebook for a concrete example of creating a custom gym environment.
Some basic advice:
- always normalize your observation space when you can, i.e., when you know the boundaries
- normalize your action space and make it symmetric when continuous (cf potential issue below) A good practice is to rescale your actions to lie in [-1, 1]. This does not limit you as you can easily rescale the action inside the environment
- start with shaped reward (i.e. informative reward) and simplified version of your problem
- debug with random actions to check that your environment works and follows the gym interface:
We provide a helper to check that your environment runs without error:
from stable_baselines.common.env_checker import check_env
env = CustomEnv(arg1, ...)
# It will check your custom environment and output additional warnings if needed
check_env(env)
If you want to quickly try a random agent on your environment, you can also do:
env = YourEnv()
obs = env.reset()
n_steps = 10
for _ in range(n_steps):
# Random action
action = env.action_space.sample()
obs, reward, done, info = env.step(action)
Why should I normalize the action space?
Most reinforcement learning algorithms rely on a Gaussian distribution (initially centered at 0 with std 1) for continuous actions. So, if you forget to normalize the action space when using a custom environment, this can harm learning and be difficult to debug (cf attached image and issue #473).
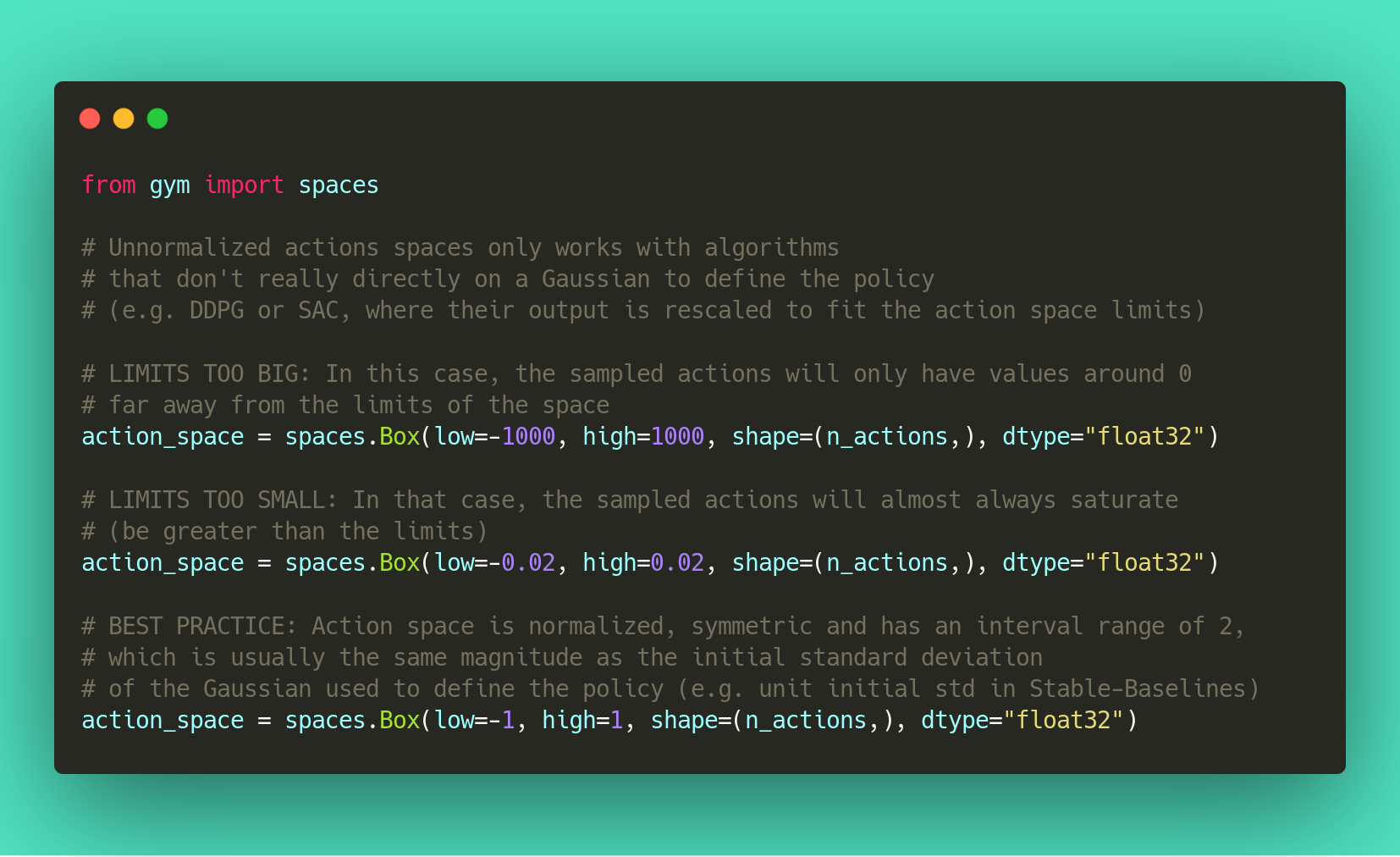
Another consequence of using a Gaussian is that the action range is not bounded.
That’s why clipping is usually used as a bandage to stay in a valid interval.
A better solution would be to use a squashing function (cf SAC) or a Beta distribution (cf issue #112).
Note
This statement is not true for DDPG or TD3 because they don’t rely on any probability distribution.
Tips and Tricks when implementing an RL algorithm¶
When you try to reproduce a RL paper by implementing the algorithm, the nuts and bolts of RL research by John Schulman are quite useful (video).
We recommend following those steps to have a working RL algorithm:
- Read the original paper several times
- Read existing implementations (if available)
- Try to have some “sign of life” on toy problems
- Validate the implementation by making it run on harder and harder envs (you can compare results against the RL zoo)
- You usually need to run hyperparameter optimization for that step.
You need to be particularly careful on the shape of the different objects you are manipulating (a broadcast mistake will fail silently cf issue #75) and when to stop the gradient propagation.
A personal pick (by @araffin) for environments with gradual difficulty in RL with continuous actions:
- Pendulum (easy to solve)
- HalfCheetahBullet (medium difficulty with local minima and shaped reward)
- BipedalWalkerHardcore (if it works on that one, then you can have a cookie)
in RL with discrete actions:
- CartPole-v1 (easy to be better than random agent, harder to achieve maximal performance)
- LunarLander
- Pong (one of the easiest Atari game)
- other Atari games (e.g. Breakout)