Examples¶
Try it online with Colab Notebooks!¶
All the following examples can be executed online using Google colab  notebooks:
notebooks:
Basic Usage: Training, Saving, Loading¶
In the following example, we will train, save and load a DQN model on the Lunar Lander environment.


Lunar Lander Environment
Note
LunarLander requires the python package box2d.
You can install it using apt install swig and then pip install box2d box2d-kengz
Note
load function re-creates model from scratch on each call, which can be slow.
If you need to e.g. evaluate same model with multiple different sets of parameters, consider
using load_parameters instead.
import gym
from stable_baselines import DQN
from stable_baselines.common.evaluation import evaluate_policy
# Create environment
env = gym.make('LunarLander-v2')
# Instantiate the agent
model = DQN('MlpPolicy', env, learning_rate=1e-3, prioritized_replay=True, verbose=1)
# Train the agent
model.learn(total_timesteps=int(2e5))
# Save the agent
model.save("dqn_lunar")
del model # delete trained model to demonstrate loading
# Load the trained agent
model = DQN.load("dqn_lunar")
# Evaluate the agent
mean_reward, std_reward = evaluate_policy(model, model.get_env(), n_eval_episodes=10)
# Enjoy trained agent
obs = env.reset()
for i in range(1000):
action, _states = model.predict(obs)
obs, rewards, dones, info = env.step(action)
env.render()
Multiprocessing: Unleashing the Power of Vectorized Environments¶

CartPole Environment
import gym
import numpy as np
from stable_baselines.common.policies import MlpPolicy
from stable_baselines.common.vec_env import SubprocVecEnv
from stable_baselines.common import set_global_seeds, make_vec_env
from stable_baselines import ACKTR
def make_env(env_id, rank, seed=0):
"""
Utility function for multiprocessed env.
:param env_id: (str) the environment ID
:param num_env: (int) the number of environments you wish to have in subprocesses
:param seed: (int) the inital seed for RNG
:param rank: (int) index of the subprocess
"""
def _init():
env = gym.make(env_id)
env.seed(seed + rank)
return env
set_global_seeds(seed)
return _init
if __name__ == '__main__':
env_id = "CartPole-v1"
num_cpu = 4 # Number of processes to use
# Create the vectorized environment
env = SubprocVecEnv([make_env(env_id, i) for i in range(num_cpu)])
# Stable Baselines provides you with make_vec_env() helper
# which does exactly the previous steps for you:
# env = make_vec_env(env_id, n_envs=num_cpu, seed=0)
model = ACKTR(MlpPolicy, env, verbose=1)
model.learn(total_timesteps=25000)
obs = env.reset()
for _ in range(1000):
action, _states = model.predict(obs)
obs, rewards, dones, info = env.step(action)
env.render()
Using Callback: Monitoring Training¶
Note
We recommend reading the Callback section
You can define a custom callback function that will be called inside the agent. This could be useful when you want to monitor training, for instance display live learning curves in Tensorboard (or in Visdom) or save the best agent. If your callback returns False, training is aborted early.
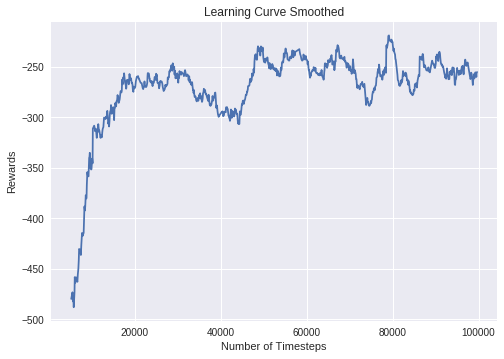
Learning curve of DDPG on LunarLanderContinuous environment
import os
import gym
import numpy as np
import matplotlib.pyplot as plt
from stable_baselines import DDPG
from stable_baselines.ddpg.policies import LnMlpPolicy
from stable_baselines import results_plotter
from stable_baselines.bench import Monitor
from stable_baselines.results_plotter import load_results, ts2xy
from stable_baselines.common.noise import AdaptiveParamNoiseSpec
from stable_baselines.common.callbacks import BaseCallback
class SaveOnBestTrainingRewardCallback(BaseCallback):
"""
Callback for saving a model (the check is done every ``check_freq`` steps)
based on the training reward (in practice, we recommend using ``EvalCallback``).
:param check_freq: (int)
:param log_dir: (str) Path to the folder where the model will be saved.
It must contains the file created by the ``Monitor`` wrapper.
:param verbose: (int)
"""
def __init__(self, check_freq: int, log_dir: str, verbose=1):
super(SaveOnBestTrainingRewardCallback, self).__init__(verbose)
self.check_freq = check_freq
self.log_dir = log_dir
self.save_path = os.path.join(log_dir, 'best_model')
self.best_mean_reward = -np.inf
def _init_callback(self) -> None:
# Create folder if needed
if self.save_path is not None:
os.makedirs(self.save_path, exist_ok=True)
def _on_step(self) -> bool:
if self.n_calls % self.check_freq == 0:
# Retrieve training reward
x, y = ts2xy(load_results(self.log_dir), 'timesteps')
if len(x) > 0:
# Mean training reward over the last 100 episodes
mean_reward = np.mean(y[-100:])
if self.verbose > 0:
print("Num timesteps: {}".format(self.num_timesteps))
print("Best mean reward: {:.2f} - Last mean reward per episode: {:.2f}".format(self.best_mean_reward, mean_reward))
# New best model, you could save the agent here
if mean_reward > self.best_mean_reward:
self.best_mean_reward = mean_reward
# Example for saving best model
if self.verbose > 0:
print("Saving new best model to {}".format(self.save_path))
self.model.save(self.save_path)
return True
# Create log dir
log_dir = "tmp/"
os.makedirs(log_dir, exist_ok=True)
# Create and wrap the environment
env = gym.make('LunarLanderContinuous-v2')
env = Monitor(env, log_dir)
# Add some param noise for exploration
param_noise = AdaptiveParamNoiseSpec(initial_stddev=0.1, desired_action_stddev=0.1)
# Because we use parameter noise, we should use a MlpPolicy with layer normalization
model = DDPG(LnMlpPolicy, env, param_noise=param_noise, verbose=0)
# Create the callback: check every 1000 steps
callback = SaveOnBestTrainingRewardCallback(check_freq=1000, log_dir=log_dir)
# Train the agent
time_steps = 1e5
model.learn(total_timesteps=int(time_steps), callback=callback)
results_plotter.plot_results([log_dir], time_steps, results_plotter.X_TIMESTEPS, "DDPG LunarLander")
plt.show()
Atari Games¶
Trained A2C agent on Breakout

Pong Environment
Training a RL agent on Atari games is straightforward thanks to make_atari_env helper function.
It will do all the preprocessing
and multiprocessing for you.
from stable_baselines.common.cmd_util import make_atari_env
from stable_baselines.common.vec_env import VecFrameStack
from stable_baselines import ACER
# There already exists an environment generator
# that will make and wrap atari environments correctly.
# Here we are also multiprocessing training (num_env=4 => 4 processes)
env = make_atari_env('PongNoFrameskip-v4', num_env=4, seed=0)
# Frame-stacking with 4 frames
env = VecFrameStack(env, n_stack=4)
model = ACER('CnnPolicy', env, verbose=1)
model.learn(total_timesteps=25000)
obs = env.reset()
while True:
action, _states = model.predict(obs)
obs, rewards, dones, info = env.step(action)
env.render()
PyBullet: Normalizing input features¶
Normalizing input features may be essential to successful training of an RL agent (by default, images are scaled but not other types of input), for instance when training on PyBullet environments. For that, a wrapper exists and will compute a running average and standard deviation of input features (it can do the same for rewards).
Note
you need to install pybullet with pip install pybullet
import os
import gym
import pybullet_envs
from stable_baselines.common.vec_env import DummyVecEnv, VecNormalize
from stable_baselines import PPO2
env = DummyVecEnv([lambda: gym.make("HalfCheetahBulletEnv-v0")])
# Automatically normalize the input features and reward
env = VecNormalize(env, norm_obs=True, norm_reward=True,
clip_obs=10.)
model = PPO2('MlpPolicy', env)
model.learn(total_timesteps=2000)
# Don't forget to save the VecNormalize statistics when saving the agent
log_dir = "/tmp/"
model.save(log_dir + "ppo_halfcheetah")
stats_path = os.path.join(log_dir, "vec_normalize.pkl")
env.save(stats_path)
# To demonstrate loading
del model, env
# Load the agent
model = PPO2.load(log_dir + "ppo_halfcheetah")
# Load the saved statistics
env = DummyVecEnv([lambda: gym.make("HalfCheetahBulletEnv-v0")])
env = VecNormalize.load(stats_path, env)
# do not update them at test time
env.training = False
# reward normalization is not needed at test time
env.norm_reward = False
Custom Policy Network¶
Stable baselines provides default policy networks for images (CNNPolicies) and other type of inputs (MlpPolicies). However, you can also easily define a custom architecture for the policy network (see custom policy section):
import gym
from stable_baselines.common.policies import FeedForwardPolicy
from stable_baselines.common.vec_env import DummyVecEnv
from stable_baselines import A2C
# Custom MLP policy of three layers of size 128 each
class CustomPolicy(FeedForwardPolicy):
def __init__(self, *args, **kwargs):
super(CustomPolicy, self).__init__(*args, **kwargs,
net_arch=[dict(pi=[128, 128, 128], vf=[128, 128, 128])],
feature_extraction="mlp")
model = A2C(CustomPolicy, 'LunarLander-v2', verbose=1)
# Train the agent
model.learn(total_timesteps=100000)
Accessing and modifying model parameters¶
You can access model’s parameters via load_parameters and get_parameters functions, which
use dictionaries that map variable names to NumPy arrays.
These functions are useful when you need to e.g. evaluate large set of models with same network structure, visualize different layers of the network or modify parameters manually.
You can access original Tensorflow Variables with function get_parameter_list.
Following example demonstrates reading parameters, modifying some of them and loading them to model
by implementing evolution strategy
for solving CartPole-v1 environment. The initial guess for parameters is obtained by running
A2C policy gradient updates on the model.
import gym
import numpy as np
from stable_baselines import A2C
def mutate(params):
"""Mutate parameters by adding normal noise to them"""
return dict((name, param + np.random.normal(size=param.shape))
for name, param in params.items())
def evaluate(env, model):
"""Return mean fitness (sum of episodic rewards) for given model"""
episode_rewards = []
for _ in range(10):
reward_sum = 0
done = False
obs = env.reset()
while not done:
action, _states = model.predict(obs)
obs, reward, done, info = env.step(action)
reward_sum += reward
episode_rewards.append(reward_sum)
return np.mean(episode_rewards)
# Create env
env = gym.make('CartPole-v1')
# Create policy with a small network
model = A2C('MlpPolicy', env, ent_coef=0.0, learning_rate=0.1,
policy_kwargs={'net_arch': [8, ]})
# Use traditional actor-critic policy gradient updates to
# find good initial parameters
model.learn(total_timesteps=5000)
# Get the parameters as the starting point for ES
mean_params = model.get_parameters()
# Include only variables with "/pi/" (policy) or "/shared" (shared layers)
# in their name: Only these ones affect the action.
mean_params = dict((key, value) for key, value in mean_params.items()
if ("/pi/" in key or "/shared" in key))
for iteration in range(10):
# Create population of candidates and evaluate them
population = []
for population_i in range(100):
candidate = mutate(mean_params)
# Load new policy parameters to agent.
# Tell function that it should only update parameters
# we give it (policy parameters)
model.load_parameters(candidate, exact_match=False)
fitness = evaluate(env, model)
population.append((candidate, fitness))
# Take top 10% and use average over their parameters as next mean parameter
top_candidates = sorted(population, key=lambda x: x[1], reverse=True)[:10]
mean_params = dict(
(name, np.stack([top_candidate[0][name] for top_candidate in top_candidates]).mean(0))
for name in mean_params.keys()
)
mean_fitness = sum(top_candidate[1] for top_candidate in top_candidates) / 10.0
print("Iteration {:<3} Mean top fitness: {:.2f}".format(iteration, mean_fitness))
Recurrent Policies¶
This example demonstrate how to train a recurrent policy and how to test it properly.
Warning
One current limitation of recurrent policies is that you must test them with the same number of environments they have been trained on.
from stable_baselines import PPO2
# For recurrent policies, with PPO2, the number of environments run in parallel
# should be a multiple of nminibatches.
model = PPO2('MlpLstmPolicy', 'CartPole-v1', nminibatches=1, verbose=1)
model.learn(50000)
# Retrieve the env
env = model.get_env()
obs = env.reset()
# Passing state=None to the predict function means
# it is the initial state
state = None
# When using VecEnv, done is a vector
done = [False for _ in range(env.num_envs)]
for _ in range(1000):
# We need to pass the previous state and a mask for recurrent policies
# to reset lstm state when a new episode begin
action, state = model.predict(obs, state=state, mask=done)
obs, reward , done, _ = env.step(action)
# Note: with VecEnv, env.reset() is automatically called
# Show the env
env.render()
Hindsight Experience Replay (HER)¶
For this example, we are using Highway-Env by @eleurent.
The highway-parking-v0 environment.
The parking env is a goal-conditioned continuous control task, in which the vehicle must park in a given space with the appropriate heading.
Note
the hyperparameters in the following example were optimized for that environment.
import gym
import highway_env
import numpy as np
from stable_baselines import HER, SAC, DDPG, TD3
from stable_baselines.ddpg import NormalActionNoise
env = gym.make("parking-v0")
# Create 4 artificial transitions per real transition
n_sampled_goal = 4
# SAC hyperparams:
model = HER('MlpPolicy', env, SAC, n_sampled_goal=n_sampled_goal,
goal_selection_strategy='future',
verbose=1, buffer_size=int(1e6),
learning_rate=1e-3,
gamma=0.95, batch_size=256,
policy_kwargs=dict(layers=[256, 256, 256]))
# DDPG Hyperparams:
# NOTE: it works even without action noise
# n_actions = env.action_space.shape[0]
# noise_std = 0.2
# action_noise = NormalActionNoise(mean=np.zeros(n_actions), sigma=noise_std * np.ones(n_actions))
# model = HER('MlpPolicy', env, DDPG, n_sampled_goal=n_sampled_goal,
# goal_selection_strategy='future',
# verbose=1, buffer_size=int(1e6),
# actor_lr=1e-3, critic_lr=1e-3, action_noise=action_noise,
# gamma=0.95, batch_size=256,
# policy_kwargs=dict(layers=[256, 256, 256]))
model.learn(int(2e5))
model.save('her_sac_highway')
# Load saved model
model = HER.load('her_sac_highway', env=env)
obs = env.reset()
# Evaluate the agent
episode_reward = 0
for _ in range(100):
action, _ = model.predict(obs)
obs, reward, done, info = env.step(action)
env.render()
episode_reward += reward
if done or info.get('is_success', False):
print("Reward:", episode_reward, "Success?", info.get('is_success', False))
episode_reward = 0.0
obs = env.reset()
Continual Learning¶
You can also move from learning on one environment to another for continual learning
(PPO2 on DemonAttack-v0, then transferred on SpaceInvaders-v0):
from stable_baselines.common.cmd_util import make_atari_env
from stable_baselines import PPO2
# There already exists an environment generator
# that will make and wrap atari environments correctly
env = make_atari_env('DemonAttackNoFrameskip-v4', num_env=8, seed=0)
model = PPO2('CnnPolicy', env, verbose=1)
model.learn(total_timesteps=10000)
obs = env.reset()
for i in range(1000):
action, _states = model.predict(obs)
obs, rewards, dones, info = env.step(action)
env.render()
# Close the processes
env.close()
# The number of environments must be identical when changing environments
env = make_atari_env('SpaceInvadersNoFrameskip-v4', num_env=8, seed=0)
# change env
model.set_env(env)
model.learn(total_timesteps=10000)
obs = env.reset()
while True:
action, _states = model.predict(obs)
obs, rewards, dones, info = env.step(action)
env.render()
env.close()
Record a Video¶
Record a mp4 video (here using a random agent).
Note
It requires ffmpeg or avconv to be installed on the machine.
import gym
from stable_baselines.common.vec_env import VecVideoRecorder, DummyVecEnv
env_id = 'CartPole-v1'
video_folder = 'logs/videos/'
video_length = 100
env = DummyVecEnv([lambda: gym.make(env_id)])
obs = env.reset()
# Record the video starting at the first step
env = VecVideoRecorder(env, video_folder,
record_video_trigger=lambda x: x == 0, video_length=video_length,
name_prefix="random-agent-{}".format(env_id))
env.reset()
for _ in range(video_length + 1):
action = [env.action_space.sample()]
obs, _, _, _ = env.step(action)
# Save the video
env.close()
Bonus: Make a GIF of a Trained Agent¶
Note
For Atari games, you need to use a screen recorder such as Kazam. And then convert the video using ffmpeg
import imageio
import numpy as np
from stable_baselines import A2C
model = A2C("MlpPolicy", "LunarLander-v2").learn(100000)
images = []
obs = model.env.reset()
img = model.env.render(mode='rgb_array')
for i in range(350):
images.append(img)
action, _ = model.predict(obs)
obs, _, _ ,_ = model.env.step(action)
img = model.env.render(mode='rgb_array')
imageio.mimsave('lander_a2c.gif', [np.array(img) for i, img in enumerate(images) if i%2 == 0], fps=29)